- Loading...
Shenandoah GC
Shenandoah is an ultra-low pause time garbage collector that reduces GC pause times by performing more garbage collection work concurrently with the running Java program. CMS and G1 both perform concurrent marking of live objects. Shenandoah adds concurrent compaction, which means its pause times are no longer proportional to the size of the heap. Garbage collecting a 100 GB heap or a 2 GB heap has the same predictable pause behavior.
Shenandoah is available in source and binary forms in JDK 8u, JDK 9, JDK 10, and JDK 11 flavors, see the "Build and Run" section for more details.
Overview
Shenandoah is the regionalized collector, it maintains the heap as the collection of regions.
The regular Shenandoah GC cycle looks like this:

GC(3) Pause Init Mark 0.771ms GC(3) Concurrent marking 76480M->77212M(102400M) 633.213ms GC(3) Pause Final Mark 1.821ms GC(3) Concurrent cleanup 77224M->66592M(102400M) 3.112ms GC(3) Concurrent evacuation 66592M->75640M(102400M) 405.312ms GC(3) Pause Init Update Refs 0.084ms GC(3) Concurrent update references 75700M->76424M(102400M) 354.341ms GC(3) Pause Final Update Refs 0.409ms GC(3) Concurrent cleanup 76244M->56620M(102400M) 12.242ms
The phases above do roughly this:
- Init Mark initiates the concurrent marking. It prepares the heap and application threads for concurrent mark, and then scans the root set. This is the first pause in the cycle, and the most dominant consumer is the root set scan. Therefore, its duration is dependent on the root set size.
- Concurrent Marking walks over the heap, and traces reachable objects. This phase runs alongside the application, and its duration is dependent on the number of live objects and the structure of object graph in the heap. Since the application is free to allocate new data during this phase, the heap occupancy goes up during concurrent marking.
- Final Mark finishes the concurrent marking by draining all pending marking/update queues and re-scanning the root set. It also initializes evacuation by figuring out the regions to be evacuated (collection set), pre-evacuating some roots, and generally prepares runtime for the next phase. Part of this work can be done concurrently during Concurrent precleaning phase. This is the second pause in the cycle, and the most dominant time consumers here are draining the queues and scanning the root set.
- Concurrent Cleanup reclaims immediate garbage regions – that is, the regions where no live objects are present, as detected after the concurrent mark.
- Concurrent Evacuation copies the objects out of collection set to other regions. This is the major difference against other OpenJDK GCs. This phase is again running along with application, and so application is free to allocate. Its duration is dependent on the size of chosen collection set for the cycle.
- Init Update Refs initializes the update references phase. It does almost nothing except making sure all GC and applications threads have finished evacuation, and then preparing GC for next phase. This is the third pause in the cycle, the shortest of them all.
- Concurrent Update References walks over the heap, and updates the references to objects that were moved during concurrent evacuation. This is the major difference against other OpenJDK GCs. Its duration is dependent on number of objects in heap, but not the object graph structure, because it scans the heap linearly. This phase runs concurrently with the application.
- Final Update Refs finishes the update references phase by re-updating the existing root set. It also recycles the regions from the collection set, because now heap does not have references to (stale) objects to them. This is the last pause in the cycle, and its duration is dependent on the size of root set.
- Concurrent Cleanup reclaims the collection set regions, which now have no references to.
Root set includes: thread local variables, references embedded in generated code, interned Strings, references from classloaders (e.g. static final references), JNI references, JVMTI references. Having larger root set generally means longer pauses with Shenandoah, see below for diagnostic techniques.
Performance Guidelines and Diagnostics
This section describes the approaches to test and diagnose performance behaviors with Shenandoah.
Basic configuration and command line options:
- Shenandoah performance, like the performance of almost all other GCs, depends on heap size. It should perform better in cases when there is enough heap space to accommodate allocations while concurrent phases are running (see "Failure Modes" section below). The time for concurrent phases correlates with the live data set size (LDS) -- the space taken by live data. Therefore, the reasonable heap size is dependent on LDS and allocation pressure in the workload: for a given allocation rate, larger LDS-es require proportionally larger heap sizes; for a given LDS, larger allocation rates require larger heap sizes. For some workloads with minuscule live data sets and moderate allocation pressure, 1...2 GB heaps performs well. We routinely test on 4...128 GB heaps on various workloads with up to 80% LDS size. Don't be shy to try different heap sizes to see what fits your workload.
- -Xlog:gc would print the individual GC timings. This is not specific to Shenandoah, most recent GCs with JDK 9 Unified Logging would work like that.
- -Xlog:gc+ergo would print the heuristics decisions, which might shed light on outliers, if any.
- -Xlog:gc+stats would print the summary table on Shenandoah internal timings at the end of the run.
It is almost always a good idea to run with -Xlog:gc -Xlog:gc+ergo -Xlog:gc+stats for testing. This summary table conveys important information about GC performance, and we would almost inevitably ask for one in a performance bug report. Heuristics logs are useful to figure out GC outliers.
Other recommended JVM options are:
- -XX:+AlwaysPreTouch: committing all pages into memory helps to reduce latency hiccups
- -XX:+UseTransparentHugePages: this greatly improves performance on large heaps. It is recommended to set /sys/kernel/mm/transparent_hugepage/enabled and /sys/kernel/mm/transparent_hugepage/defrag to "madvise" on Linux. When running with AlwaysPreTouch, then init/shutdown would be faster, because it will pretouch with larger pages. It will also pay the defrag costs upfront at startup
- -XX:+UseNUMA: while Shenandoah does not support NUMA explicitly yet, it is a good idea to enable this to enable NUMA interleaving on multi-socket hosts. Coupled with AlwaysPreTouch, it provides better performance than the default out-of-the-box configuration
- -XX:-UseBiasedLocking: there is a tradeoff between uncontended (biased) locking throughput, and the safepoints JVM does to enable and disable them as needed. For latency-oriented workloads, it makes sense to turn biased locking off.
- -XX:+DisableExplicitGC: invoking System.gc() from user code forces Shenandoah to perform STW Full GC, which is detrimental to GC pauses; it makes sense to disable this to protect from libraries that do this. There is an alternative -XX:+ExplicitGCInvokesConcurrent, that can force concurrent cycle instead of Full GC on System.gc(), you are advised to use that in cases System.gc() calls do matter.
Heuristics
Heuristics tell when Shenandoah starts the GC cycle, and regions it deems for evacuation. Heuristics can be selected with -XX:ShenandoahGCHeuristics=<name>. Some heuristics accept configuration parameters, which might help to tailor the GC operation to your use case better. Available heuristics include:
- adaptive (default). This heuristics observes the previous GC cycles, and tries to start the next GC cycle so that the free space available at all times was below the "free threshold". Useful tuning knobs are:
-XX:ShenandoahInitFreeThreshold=#: Initial remaining free threshold
-XX:ShenandoahMinFreeThreshold=#: Minimum remaining free threshold
-XX:ShenandoahMaxFreeThreshold=#: Maximum remaining free threshold
-XX:ShenandoahHappyCyclesThreshold=#: How many successful marking cycles before improving free threshold
-XX:ShenandoahGarbageThreshold=#: Sets the percentage of garbage a region need to contain before it can be marked for collection.
- static (previously and ironically known as dynamic). This heuristics decide to start GC cycle based on heap occupancy and allocation pressure. Useful tuning knobs for this heuristics are:
-XX:ShenandoahFreeThreshold=#: Set the percentage of free heap at which a GC cycle is started
-XX:ShenandoahAllocationThreshold=#: Set percentage of memory allocated since last GC cycle before a new GC cycle is started
- -XX:ShenandoahGarbageThreshold=#: Sets the percentage of garbage a region need to contain before it can be marked for collection
compact (previously erroneously known as continuous). This heuristics runs GC cycles continuously, starting the next cycle as soon as previous cycle finishes, as long as allocations happen. This heuristics would normally incur throughput overheads, but shall provide the most prompt space reclamation. Useful tuning knobs are:
-XX:ConcGCThreads=#: Trim down the number of concurrent GC threads to make more room for application to run
-XX:ShenandoahAllocationThreshold=#: Set percentage of memory allocated since last GC cycle before starting another one
- passive (diagnostic). This heuristics tells GC to be completely passive. Once available memory runs out, Full Stop-The-World GC would be triggered. This heuristics is used for functional testing, but sometimes it is useful for bisecting performance anomalies with GC barriers (see below), or figuring out the actual live data size in the application.
- aggressive (diagnostic). This heuristics tells GC to be completely active. It will start the new GC cycle as soon as the previous one finishes (like "continuous"), and it will evacuate all live objects. This heuristics is useful for functional testing of the collector itself. It incurs heavy performance penalty.
- connected, generational, LRU (experimental). These are heuristics for partial collections that use the heap connectivity information to drive collections. These heuristics are heavily experimental, and may be less stable or less performant than the default. "Connectedness" focuses on least connected regions, "generational" focuses on younger regions, "LRU" focuses on older regions.
In some cycles, Update References phase is merged with Concurrent Marking phase, at heuristics discretion. You can forcefully enable/disable Update References with -XX:ShenandoahUpdateRefsEarly=[on|off].
Failure Modes
Concurrent GC like Shenandoah implicitly relies on collecting faster than application allocates. If allocation pressure is high, and there is not enough space to absorb allocations while GC is running, Allocation Failure would eventually happen. Shenandoah has a graceful degradation ladder that helps to alleviate the costs. The ladder consists of:
- Pacing (-XX:+ShenandoahPacing, enabled by default). When GC is running, it has the idea how much GC work is needed to be done, and how much free space is available for application. Pacer would try to stall allocating threads when the GC progress is not fast enough. Note that this introduces the local per-thread latency that is not visible in usual profiling tools. This is why the stalls are not indefinite, and they are bounded by -XX:ShenandoahPacingMaxDelay=#ms. After the max delay is expired, the allocation would happen anyway. Most of the time, mild allocation spikes are absorbed by the pacer. When allocation pressure is very high, pacer would not be able to cope, and the degradation moves to the next step.
Usual latency induced: <10 ms - Degenerated GC (-XX:+ShenandoahDegeneratedGC, enabled by default). If application runs into allocation failure, then Shenandoah would dive into stop-the-world pause, stop the entire application, and continue the cycle under the pause. The Degenerated cycle might be faster than the concurrent one, because it does not contend with the application over the resources, and it uses -XX:ParallelGCThreads, not -XX:ConcCGThreads for thread pool sizing. In many cases, Degenerated cycles happen after a significant amount of GC work is already done. This is why the STW pause is not usually large. It would be reported as GC pause in the GC log. Degenerated GC may happen if GC cycle started too late, or if a very significant allocation spike had occurred.
Usual latency induced: <100 ms, but can be more, depending on the degeneration point - Full GC. If nothing helped, for example, when Degenerated GC had not freed up enough memory, Full GC cycle would happen, and compact the heap to the max. Certain scenarios, like the unusually fragmented heap would be fixed only by Full GC.
Usual latency induced: >100 ms, but can be more, especially on a very occupied heap
For example, -Xlog:gc+stats would show something like this at the end of the run:
Under allocation pressure, concurrent cycles may cancel, and either continue cycle
under stop-the-world pause or result in stop-the-world Full GC. Increase heap size,
tune GC heuristics, set more aggressive pacing delay, or lower allocation rate
to avoid Degenerated and Full GC cycles.
4912 successful concurrent GCs
0 invoked explicitly
3 Degenerated GCs
3 caused by allocation failure
3 happened at Update Refs
0 upgraded to Full GC
0 Full GCs
0 invoked explicitly
0 caused by allocation failure
0 upgraded from Degenerated GC
ALLOCATION PACING:
Max pacing delay is set for 10 ms.
Higher delay would prevent application outpacing the GC, but it will hide the GC latencies
from the STW pause times. Pacing affects the individual threads, and so it would also be
invisible to the usual profiling tools, but would add up to end-to-end application latency.
Raise max pacing delay with care.
Actual pacing delays histogram:
From - To Count
1 ms - 2 ms: 87
2 ms - 4 ms: 142
4 ms - 8 ms: 297
8 ms - 16 ms: 1733
16 ms - 32 ms: 21
32 ms - 64 ms: 1
From this, there are a few things to try if application runs into either of these degradation steps:
- Give the application more heap. This would allow to absorb more allocations when GC is running.
- Trim down the amount of live data in the heap. This would allow GC cycle to run faster, and cope with allocations better.
- Trim down the allocation pressure. For example, reduce the number of allocating threads, or fix the major allocation hogs in the application.
- Tune up heuristics to start the GC cycle as soon as possible. It might not help if GC logs already say that GC is running back-to-back cycles.
- Crank up the pacing delay. This would stall allocating threads more, instead of elevating to Degenerated and Full GCs – note this still introduce latency for those allocating threads!
Performance Analysis
Approaches to performance analysis:
- Some odd performance behaviors – like the allocation failure GCs, or long final marks – can be explained by heuristics issues. -Xlog:gc+ergo is your friend there. If you have a long-running workload, running under Shenandoah Visualizer would let you understand the high-level GC behavior. Sometimes the odd behavior is clearly visible there.
- Some performance difference can be explained by larger allocation pressure under Shenandoah, since it includes the forwarding pointer with each object. Look at the allocation rates to see if that might be a problem, and do experiments that could confirm this (for example, beefing up objects should diminish the performance difference against another collector). There are some cases when larger footprint means dropping out of CPU cache, look for L1/L2/LLC miss differences.
Many throughput differences can be explained by GC barriers overhead. When running with -XX:ShenandoahGCHeuristics=passive, and that heuristics only, barriers are not required for correctness, and so heuristics disables them. It is then possible to enable the barriers selectively back, and see what barriers are affecting throughput performance. The list of barriers that "passive" heuristics is disabling is listed in GC output, like this:
$ java -XX:+UseShenandoahGC -XX:ShenandoahGCHeuristics=passive -Xlog:gc [0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahSATBBarrier by default [0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahKeepAliveBarrier by default [0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahWriteBarrier by default [0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahReadBarrier by default [0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahStoreValReadBarrier by default [0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahCASBarrier by default [0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahAcmpBarrier by default [0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahCloneBarrier by default [0.003s][info][gc] Using Shenandoah
- Profiling the native GC code is easy with Linux perf:
- Build OpenJDK with
--with-native-debug-symbols=internal, this will get you the mapping to C++ code - Run the workload with
perf record java ...(plain profile) orperf record -g java ...(call tree profile) - Open the report with
perf report - Navigate the report, and see where are suspiciously hot methods/paths are. Pressing
"a"on the method usually gives a more detailed disassembly for it
- Build OpenJDK with
- Profiling the barriers code requires PrintAssembly-enabled build. We recommend to use JMH -prof perfasm to create the isolated scenarios and looking at the generated code under Shenandoah.
It is important to understand that GC pauses might not be the only significant contributor to response times in regular applications. Having large GC pause spells the problem with response time with a very high probability, but the absence of long GC pauses does not always mean decent response time. Queueing delays, network latencies, other services latencies, OS scheduler jitter, etc. could be the contributing cost. Running Shenandoah with response time measurement is recommended to get the full picture of what is going on in the system, which can then be used to correlate with GC pause time statistics.
For example, this is a sample report with jHiccup on one of the workloads:
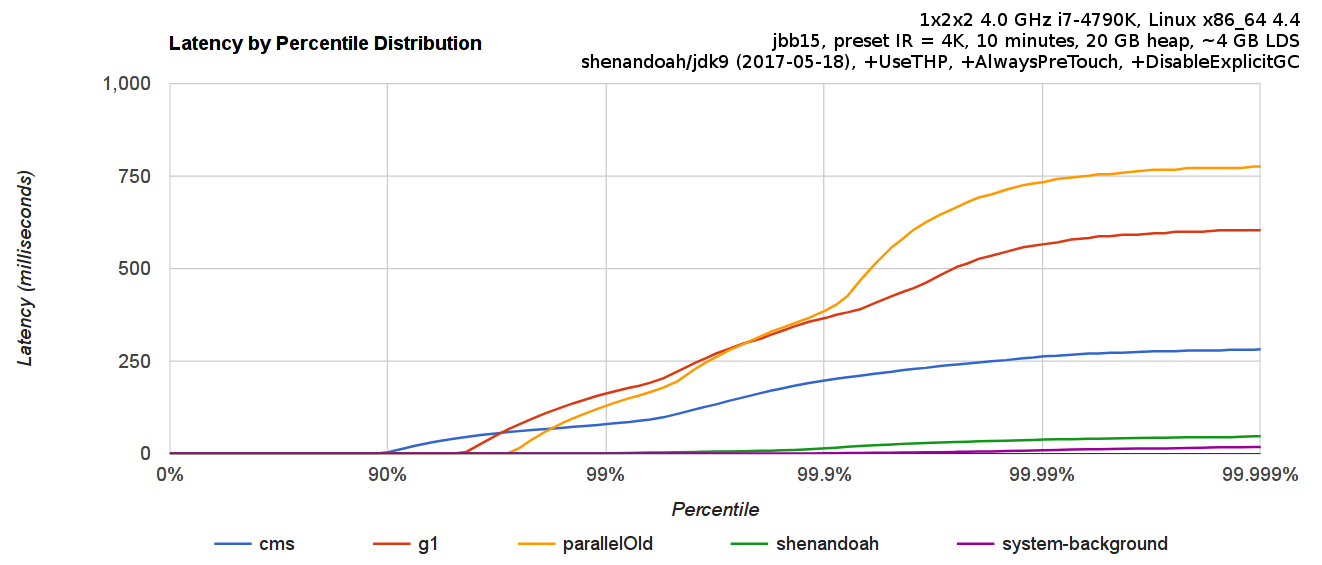
Functional Diagnostics
This section describes the ways one can diagnose and/or debug Shenandoah.
Basic configuration and command line options:
- Your first line of defense is GC verifier. It is available in both release and fastdebug builds, and can be enabled with -XX:+ShenandoahVerify. If verifier identifies a problem, then it is most likely the GC bug. A simple reproducer would be convenient to have in order to diagnose this better. In many cases, what happened before in the GC matters, e.g. the last actions taken by GC. Be sure to gather that data with GC logging.
- In many cases, running with fastdebug build will produce the meaningful assert messages, pointing at the earliest moment when GC detected the functional anomaly, and Shenandoah asserts a lot. These builds can be produced by adding --enable-debug to configure, and re-building.
- In many cases, running with -XX:ShenandoahGCHeuristics=aggressive is an efficient way to shake out GC bugs. This heuristics runs back-to-back GCs, and evacuates all non-empty regions. Since Shenandoah does most GC heavy-lifting concurrently, this does not block application from executing, although GC would consume much more cycles in this mode and slow the application down.
- It is possible to disable concurrent GCs with -XX:ShenandoahGCHeuristics=passive, which will do the stop-the-world mark-compact GCs only, and avoid doing most of concurrent work.
- Shenandoah supports several options that add even more verifications: -XX:+ShenandoahStoreCheck lets C2 compile machine code that checks that writes happen in tospace only. -XX:+ShenandoahVerifyOptoBarriers verifies barriers in C2's ideal graph. -XX:VerifyStrictOopOperations performs additional checks to verify that oop comparisons are done correctly (fastdebug only).
- If you suspect a JIT bug (and there are lots of Shenandoah-specific optimizations), it is a very good idea to try bisect which compiler failed by trying several VM modes: -Xint (interpreter only), -XX:TieredStopAtLevel=1 (C1 only), -XX:-TieredCompilation (interpreter and C2 only), default (interpreter, tiered C1, tiered C2).
Approaches for debugging:
- Put logging statements in the code around the failing assert to understand the issue better. With enough logging, you can retrace everything that happened in the collector.
- Attach a native debugger, for example, gdb, by asking VM to do the external action on failure with -XX:OnError="gdb - %p" (%p would get substituted with process PID)
- Create a simple reproducer and hand it over to Shenandoah developers. :)
Reporting Bugs
Since Shenandoah is not yet in OpenJDK mainline, and also the internal diagnostics is being worked out, the best way to report the bug is to send a message to shenandoah-dev mailing list. Please do not submit the bugs against OpenJDK itself, because Shenandoah developers do not monitor them routinely, asking the submitter about more details would be more complicated, and there is not bug category to assign the bug to. Before reporting the bug, please try to narrow it down, using the techniques from "Functional Diagnostics" and "Performance Diagnostics" sections above.
Build, Download, Install, and Run
Shenandoah is under active development outside of JDK master releases. It will hopefully enter mainline OpenJDK builds under JEP 189. That said, there are downstream builds available for current JDKs, which one can try today. The changes flow between the development repos and builds as described on a simplified diagram below. If you are an early adopter, trying a bleeding edge should be more profitable performance-wise, but may risk exposure to not-yet-discovered bugs. If you are looking at running Shenandoah in the actual deployments, using the most stable builds is preferred.

More detailed, there are different ways to get Shenandoah:
Binary Development Builds
There are (nightly/weekly) development builds available at these locations:
- Linux/x86_64 nightly builds are available at builds.shipilev.net
Linux/x86_64 builds are also available as Docker images, e.g.:
# Update the image to the most recent one: $ docker pull shipilev/openjdk-shenandoah $ docker pull shipilev/openjdk-shenandoah:10 $ docker pull shipilev/openjdk-shenandoah:9 $ docker pull shipilev/openjdk-shenandoah:8 # Run the latest version: $ docker run --rm -it shipilev/openjdk-shenandoah java -XX:+UseShenandoahGC -Xlog:gc -version [0.040s][info][gc] Using Shenandoah openjdk version "11-internal" 2018-09-18 OpenJDK Runtime Environment (build 11-internal+0-nightly-sobornost-builds.shipilev.net-shenandoah-jdkX-b4) OpenJDK 64-Bit Server VM (build 11-internal+0-nightly-sobornost-builds.shipilev.net-shenandoah-jdkX-b4, mixed mode) # JDK 10 backport: $ docker run --rm -it shipilev/openjdk-shenandoah:10 java -XX:+UseShenandoahGC -Xlog:gc -version [0.044s][info][gc] Using Shenandoah openjdk version "10-internal" 2018-03-20 OpenJDK Runtime Environment (build 10-internal+0-nightly-sobornost-builds.shipilev.net-shenandoah-jdk10-b156) OpenJDK 64-Bit Server VM (build 10-internal+0-nightly-sobornost-builds.shipilev.net-shenandoah-jdk10-b156, mixed mode) # JDK 9 backport: $ docker run --rm -it shipilev/openjdk-shenandoah:9 java -XX:+UseShenandoahGC -Xlog:gc -version [0.006s][info][gc] Using Shenandoah openjdk version "9.0.1-internal" OpenJDK Runtime Environment (build 9.0.1-internal+0-nightly-sobornost-builds.shipilev.net-shenandoah-jdk9-b105) OpenJDK 64-Bit Server VM (build 9.0.1-internal+0-nightly-sobornost-builds.shipilev.net-shenandoah-jdk9-b105, mixed mode) # JDK 8 backport: $ docker run --rm -it shipilev/openjdk-shenandoah:8 java -XX:+UseShenandoahGC -verbose:gc -version openjdk version "1.8.0-nightly" OpenJDK Runtime Environment (build 1.8.0-nightly-sobornost-builds.shipilev.net-shenandoah-jdk8-b110) OpenJDK 64-Bit Server VM (build 25.71-b110, mixed mode) Cancelling concurrent GC: Stopping VM
- Binary builds from AdoptOpenJDK: jdk8, jdk9 – look at the publish dates, the builds might be outdated
Distribution Releases
In some Linux distributions, Shenandoah is available within the OpenJDK binaries.
Fedora 24+ OpenJDK builds include Shenandoah:
$ cat /etc/redhat-release Fedora release 26 (Twenty Six) $ java -XX:+UseShenandoahGC -version openjdk version "1.8.0_131" OpenJDK Runtime Environment (build 1.8.0_131-b12) OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
- RHEL 7.4+ ships with OpenJDK that includes Shenandoah as Technology Preview
- RHEL/Fedora-based distros or other distros that use packages from them may also have Shenandoah enabled. Notably, CentOS, Oracle Linux, and Amazon Linux are known to ship it.
- Gentoo ebuilds for IcedTea have Shenandoah USE flag
- Red Hat OpenJDK builds for Windows include Shenandoah
Build From Source
This would guarantee you run the latest and greatest version. Adding --enable-debug to configure would produce the "fastdebug" build. Some features and bugfixes may not be available in older JDK versions. Older JDK versions are supposed to be more stable.
# JDK master: $ hg clone http://hg.openjdk.java.net/shenandoah/jdk shenandoah # JDK 10: $ hg clone http://hg.openjdk.java.net/shenandoah/jdk10 shenandoah # JDK 9: $ hg clone http://hg.openjdk.java.net/shenandoah/jdk9 shenandoah # JDK 8u: $ hg clone http://hg.openjdk.java.net/shenandoah/jdk8u shenandoah $ cd shenandoah/ # Configure and build, JDK 10+: $ sh ./configure $ make images # Configure and build, JDK 9-: $ sh ./get_source.sh $ sh ./configure $ make images # Run! JDK 9+: $ build/linux-x86_64-normal-server-release/images/jdk/bin/java -XX:+UseShenandoahGC -Xlog:gc [...][info][gc] Using Shenandoah # Run! JDK 8u: $ build/linux-x86_64-normal-server-release/images/j2sdk-image/bin/java -XX:+UseShenandoahGC -version openjdk version "1.8.0-internal" OpenJDK Runtime Environment (build 1.8.0-internal-shade_2016_12_19_15_52-b00) OpenJDK 64-Bit Server VM (build 25.71-b00, mixed mode)
Note: OpenJDK is normally compiled with all warnings treated as errors. Newer compilers may have more warnings that codebase had not yet caught up with. You can pass --disable-warnings-as-errors to ./configure in those cases.
In all cases for building from source it is optional, but advisable to run the tests. This is especially important on platforms beyond what Shenandoah currently targets, and/or building with too new or too old toolchains. You will need jtreg to run the tests, and it makes sense to run test against fastdebug build first:
# Download and unpack jtreg from https://adopt-openjdk.ci.cloudbees.com/job/jtreg/lastSuccessfulBuild/artifact/ # Hook up jtreg to the build: $ sh ./configure --with-jtreg=<jtreg folder> --with-debug-level=fastdebug $ sh ./configure --with-jtreg=<jtreg folder> --with-debug-level=release # Run the tests: $ CONF=linux-x86_64-normal-server-fastdebug make images test TEST="hotspot_gc_shenandoah" $ CONF=linux-x86_64-normal-server-release make images test TEST="hotspot_gc_shenandoah"
Resources
- Shenandoah Project
- Repositories
- Mailing list: shenandoah-dev
- Members
Overview
Content Tools