- Loading...
Page History
OpenJFX strives not just to be an open source project, but to be an "open development" project as well. This means transparency in planning, performance, bugs, fixes, decisions, code reviews, and more. Any committer on OpenJFX has equal privilege to any other committer and access to the same tools. As OpenJDK provides more infrastructure for open development for things like code review, OpenJFX will take advantage of it.
Tools are a big part of being a productive developer on OpenJFX and we aim to provide excellent support for all three major IDEs: NetBeans, IntelliJ IDEA, and Eclipse. Regardless of which development environment you prefer, you should find it easy to get up and running with OpenJFX. We hope you will return the favor by submitting patches and bug reports!
This section assumes that you have already succeeded in Building OpenJFX. A gradle build must complete before IDE support will fully work (otherwise your IDE will just be a glorified text editor with lots of red squiggles!). Specific instructions for using each IDE is provided below, followed by a discussion on Developer Workflow, Using Mercurial, and Communication with other members of the team. Further information on how we work can be found under Code Style Rules.
IDE Pre-Requirements
Despite the fact that most of the major IDE's support gradle directly, we have decided to provide pre-generated IDE configuration files in order to make using an IDE smooth and painless. As the IDE's support for gradle improves, we may be able to update these instructions to rely on that support instead of the checked-in project files that we have today.
IMPORTANT: Ensure that you do not have gradle plugins for NetBeans or Eclipse installed. They will conflict with the pre-generated IDE files. In furture, we may move to gradle builds within the IDE's as support becomes better.
Get a 32-bit version of the JDK
If you are building and running native libraries, the current native build produces 32-bit libraries. If you attempt to use them in a 64-bit JVM, they will fail to load and presently do not provide much indication about what went wrong. The easiest thing to do is to use a 32-bit JVM. This is not necessary on platforms like Mac that only support 64-bit JVM's.
Get an IDE that supports JDK8
OpenJFX is based on JDK1.8 and IDE support for lambdas and default methods currently requires that you get a pre-release version. IntelliJ supports this out of the box. Eclipse and NetBeans do not.
NetBeans: http://bits.netbeans.org/dev/nightly/
- this version works on Mac: netbeans-trunk-nightly-201305192300-javase-macosx.dmg
- this version works on Windows: netbeans-trunk-nightly-201305192300-javase-windows.exe
- this versions works on Linux: netbeans-trunk-nightly-201306252301-javase-linux.sh
- other versions are likely to work but these are the ones that have been tested
IntelliJ: http://www.jetbrains.com/idea/download/
Eclipse: http://wiki.eclipse.org/JDT_Core/Java8
Once you have downloaded and installed an IDE that is JDK8 aware, you will need to configure it to accept JDK8 syntax and generate the right byte codes. This will be explained later on for each particular IDE. If you use an IDE without JDK8 support, such as NetBeans 3.7.1, you will not be able to run from within the IDE.
Move jfxrt.jar to the cache directory
JavaFX is bundled with the JDK as an extension. The jfxrt.jar is located in the extension directory called 'ext' where Java is installed. You must remove it from this directory for the IDE's to work properly. The issue is this: If jfxrt.jar is in the extension directory, it will get seen before the code in your IDE. This means you won't be running or testing anything. For more information on why this is a problem, see Unique Challenges of Working on the JDK.
By moving jfxrt.jar to a standard cache directory, your IDE can reference it to find binary versions of classes that are not yet open source. Further, when both jfxrt.jar and your IDE reference a class, the class from the IDE will be chosen.
To move jrxrt.jar to the standard cache directory:
- cd <PATH TO JFX>
- mkdir -p caches/sdk/rt/lib/ext
- mv <PATH TO JDK>jre/lib/ext/jfxrt.jar caches/sdk/rt/lib/ext
Using NetBeans
Many commiters are using NetBeans to develop Java and native code. NetBeans projects have been configured for both. Native projects in NetBeans are currently not configured to build using either Make or gradle, however ant build works in NetBeans and will build the classes and jar files needed for the IDE.
Here are the steps to use NetBeans:
- Edit netbeans.conf
- Invoke NetBeans
- Add the JDK8 Platform
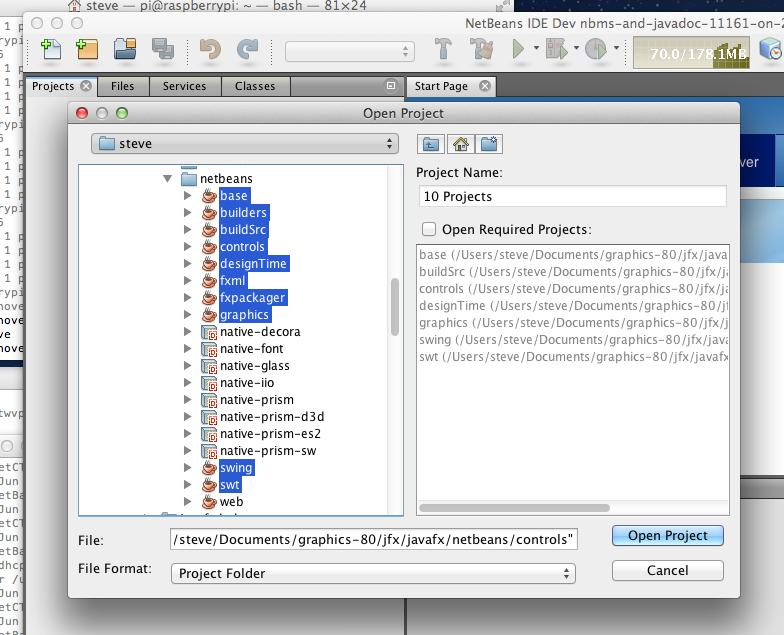
- Import NetBeans projects
- Rebuild
- Run sample code
- Run sample code with grade built shared libraries
Edit netbeans.conf
We have found the nightly versions of NetBeans to be unstable under JDK8, but fine otherwise. Further, NetBeans needs to be told not to report errors when private JDK classes referenced. The netbeans.conf file is located in the etc directory of your NetBeans install. You will edit netbeans_default_options and netbeans_jdkhome.
- Change netbeans_default_options to remove "-J-ea" and add "-J-da -J-DCachingArchiveProvider.disableCtSym=true". It does not hurt to increase memory using "-J-Xmx1024m".
- Change netbeans_jdkhome to point to a JDK7 JVM.
Here is a sample file from the Mac. The Windows and Linux default options might be a bit different.
| Code Block | ||
|---|---|---|
| ||
# Options used by NetBeans launcher by default:
# (can be overridden by explicit command line switches)
#
# Note that default -Xmx and -XX:MaxPermSize are selected for you automatically.
# You can find these values in var/log/messages.log file in your userdir.
# The automatically selected value can be overridden by specifying -J-Xmx or
# -J-XX:MaxPermSize= here or on the command line.
#
# If you specify the heap size explicitly, you may also want to enable
# Concurrent Mark & Sweep garbage collector.
# (see http://wiki.netbeans.org/FaqGCPauses)
#
netbeans_default_options="-J-client -J-Xss2m -J-Xms32m -J-XX:PermSize=32m -J-Xmx1024m -J-da -J-DCachingArchiveProvider.disableCtSym=true -J-Dnetbeans.logger.console=true -J-Dapple.laf.useScreenMenuBar=true -J-Dapple.awt.graphics.UseQuartz=true -J-Dsun.java2d.noddraw=true -J-Dsun.java2d.dpiaware=true -J-Dsun.zip.disableMemoryMapping=true -J-Dplugin.manager.check.updates=false -J-Dnetbeans.extbrowser.manual_chrome_plugin_install=yes"
# Default location of JDK:
# (set by installer or commented out if launcher should decide)
#
# It can be overridden on command line by using --jdkhome <dir>
# Be careful when changing jdkhome.
# There are two NetBeans launchers for Windows (32-bit and 64-bit) and
# installer points to one of those in the NetBeans application shortcut
# based on the Java version selected at installation time.
#
netbeans_jdkhome="/Library/Java/JavaVirtualMachines/jdk1.7.0_11.jdk/Contents/Home" |
Invoke NetBeans
Note that before you invoke NetBeans, you may need to clear your old defaults and start with a fresh NetBeans install or you might get errors.
Add the JDK8 Platform
Invoke Tools->Java Platforms
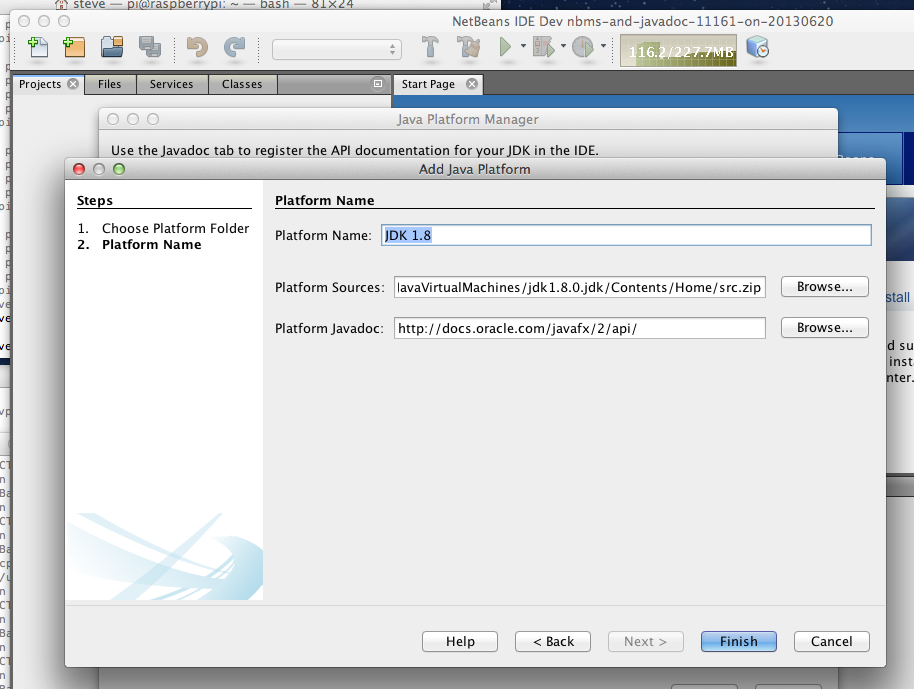
Import the NetBeans Projects
Open Project... (you may need to resolve missing junit jars, don't open web or builders for now)
Rebuild
This might take quite a long time depending on how fast your machine it. There should be no red marks on any of the projects.
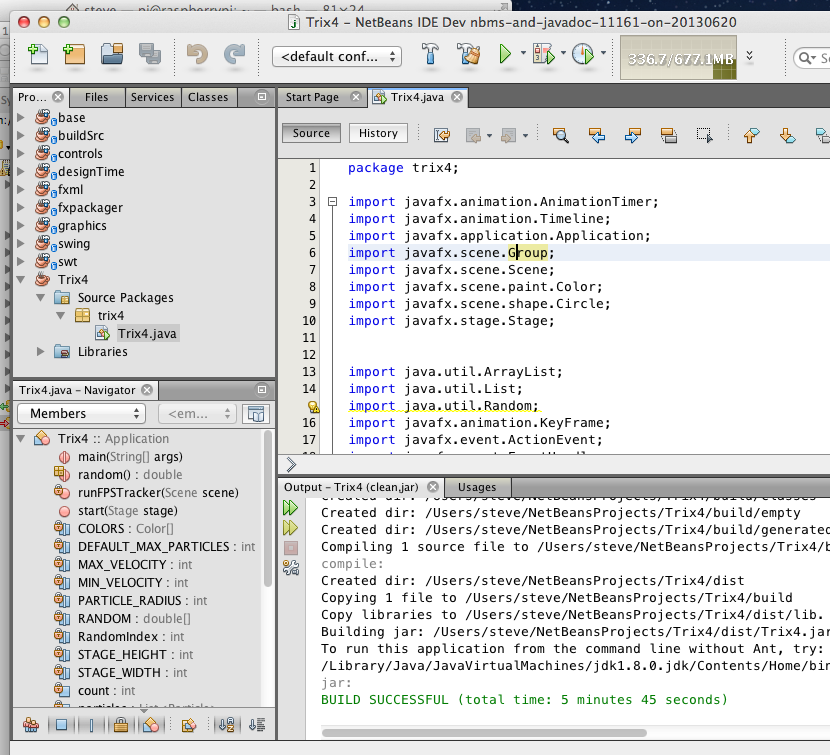
Run Sample Code
Here is some sample code that was hooked up to use the base, graphics and controls projects. When saved, these projects were built by the IDE and the same code executed using the source in the IDE.
Run Sample Code with gradle built shared libraries
//TODO - explain how to hook up the shared libraries in the run dialog
Using IntelliJ IDEA
IntelliJ is a popular IDE that is used by many committers to develop JavaFX code. An IntelliJ project has been created for you that you need to open. The steps to use IntelliJ are:
- Open the IntelliJ Project
- Make
- Run sample code
- Run sample code with grade built shared libraries
Open the IntelliJ Project

Make
Build->Make Project

Run Sample Code

Run Sample Code with Gradle Built Shared Libraries
//TODO - explain how to hook up the shared libraries in the run dialog
Using Eclipse
Eclipse is a popular IDE that is used by many committers to develop Java code. Eclipse projects have been created for you to use.
The steps to use Eclipse are:
- Import the Eclipse Projects
- Configure Eclipse to use JDK8
- Run sample code
- Run sample code with grade built shared libraries
Import the Eclipse Projects
Import->General->Existing Projects into Workspace
Check 'Search for nested projects
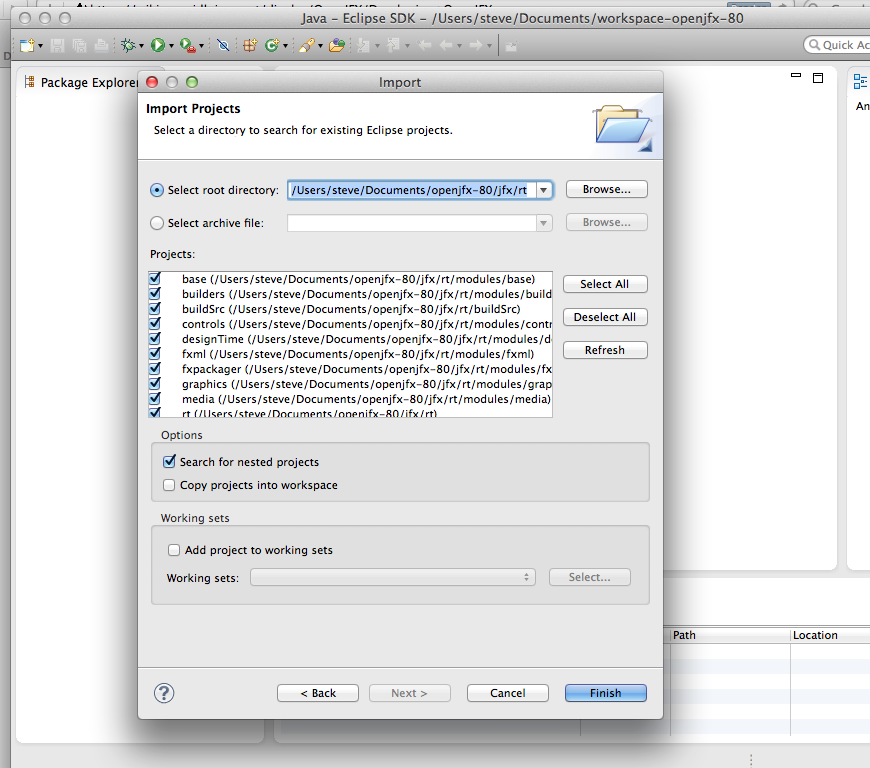
Configure Eclipse to use JDK8
Preferences->Java->Compiler->OK
IMPORTANT: The Eclipse JDK8 compiler sometimes reverts to 1.6 compliance level even though the IDE claims to be compiling 1.8. If this happens, configure Eclipse to use 1.7, then configure it to use 1.8.

Run Sample Code
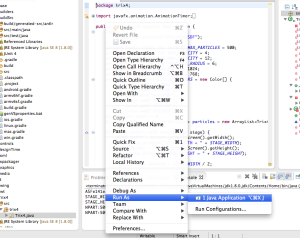
Run Sample Code with Gradle Built Shared Libraries
//TODO - explain how to hook up the shared libraries in the run dialog
//TODO - these are the VM Arguments: -Djava.library.path=${workspace_loc:rt}/build/mac-sdk/rt/lib
...
The developer workflow always begins and ends with JIRA.

Everything about an issue is captured in JIRA, whether it is a Bug, Feature, Tweak, or Task. JIRA is the database of record for OpenJFX. Any Bug, Feature, Tweak, or Task will have all comments related to the issue recorded directly on the issue, or linked to from the issue. For example, if there is an openjfx-dev mailing list thread about the issue, the issue should contain a link to the mail archives.
The first step in the workflow is to search JIRA for your issue. You may use the JIRA search functionality, or you may ask developers on openjfx-dev if an issue you see is a known issue. You may be asked to file an issue. If you do, it is important to understand the difference between a Feature, a Tweak, and a Bug.
A Feature is a significant piece of new functionality which is expected to take more than two weeks to implement, document, and test. Because features represent a significant amount of work, a development team needs to prioritize and approve work on features. Whoever proposes to work on a feature is responsible to "fund" the development, documentation, and testing. For example, if Feature X is important to you, you can take responsibility to ensure that it is developed according to guidelines and feedback from the team, develop the documentation, and develop the tests. If you do so and the feature is in harmony with the rest of the platform (we're not adding a full blown email client!) then the feature has been "self funded" by the contributor, but will still be gratefully accepted by OpenJFX. On the other hand, if all you propose is to provide the implementation, then it will be up to somebody else to agree to fund the documentation and testing before the feature can be integrated.
Features do not necessarily mean new API, they may also mean significant implementation work such as a new rendering pipeline. A Feature is never a Bug.
A Tweak is a less significant amount of work. It is somewhat like a "little feature". Tweaks can be delivered after the Feature Freeze date, even if they implement new API, as long as the amount of work to deliver the completed tweak is less than two weeks. As with Features, if a contributor wants to supply a Tweak, it is best to ensure that testing and documentation is complete, otherwise the Tweak may not be accepted.
A Bug is a defect in the code. Something is not behaving as it should. Bugs can be fixed all the way to the Code Freeze date, although with stricter guidelines the closer the Code Freeze date approaches. Sometimes the line is blurry between a Bug and a Feature, so be gentle if you need to adjust somebodies Feature to turn it into a Bug or (worse!) if you have to turn a Bug into a Feature. Use judgement and Do the Right Thing.
As a contributor, you might be done with your involvement after filing the issue. If you are not interested or capable of spending the time to supply a patch as well, we thank you! Every little contribution makes a big difference and is gratefully received.
Otherwise, it is time now to tell the Issue owner that you are interested in providing a patch. Collaborate with the owner -- they may already have something in mind that could make your job easier, and smooth the process of accepting the contribution back. Make sure people know you are working on something so that effort is not duplicated. Be responsive if people approach you about the current state of the work.
You should also make sure that you have signed and submitted an Oracle Contributor Agreement and that it has been received and processed. A committer must ensure this has been filed for any non-trivial contribution and the submitter is on the signatories list.
One excellent way to collaborate is to fork the project on BitBucket. From here you can work transparently, making your changes readily available to anybody who would like to contribute. If you need to go away for a while, let the Issue owner know so that the owner isn't waiting around for a patch that is never going to come.
Once you have a patch developed, you have two options. If you are a committer, then you should use the code review process (TBD). If you are not a committer then the best approach is to attach a diff or patch to the JIRA issue if it is very small, or a Webrev to the issue if it is larger. Or you can issue a pull request from BitBucket and provide a link to the pull request in the JIRA. From this point, the issue owner needs to provide quick feedback in the JIRA issue, a code review, and acceptance of the submission when appropriate or clear guidance on why a submission was not accepted when appropriate.
The committer who owns the issue will then be responsible for taking the patch, applying it, running the tests, and pushing the fix to the repository. The comment on the change set should be of the form:
RT-12345: Short Description of the JIRA issueSummary: Optionally provided to give more info on what is being doneSubmitted-By: Contributor email who submitted it The Summary is optional, and Submitted-By should only be used when the contribution came from somebody who is not a committer on the project.
The final step is to update the JIRA. The JIRA issue should be marked "Resolved" (not "Closed") and a comment should be added with a reference to which changeset(s) were involved. This is most helpful when it is a link to the Mercurial HTTP website for OpenJFX so that a simple click will lead to the patch.
...
Mercurial is a very powerful source control system. If you have not used Mercurial before, it is highly recommended that you download and read the free Mercurial HG RedBook. This will give you a working knowledge of how to use Mercurial from the command line, which is very useful for those cases that you run into from time to time where whatever Mercurial UI you might use day-to-day fails you.
Since cloning a fresh repository is fairly expensive, and since developers are often faced with working on several issues concurrently (perhaps one is in code review while you work on another), each developer must decide how to manage multiple concurrent patches. The most dangerous method is to have a single repository with multiple fixes in it concurrently, because the possibility of introducing a bad patch is quite high.
Because true branches in Mercurial are a permanent part of the record and pushed to all parent repositories, we never use branches in Mercurial. Rather, we either use locally cloned repos, manually managed patches, or Mercurial Queues.
Having multiple local repos is relatively straightforward. First, you clone from whatever the parent repo is you want, for example, from graphics:
| Code Block | ||
|---|---|---|
| ||
hg clone http://hg.openjdk.java.net/openjfx/8/graphics/rt /path/to/my/local/integRepo |
Then you clone from your local integration repo, once for each local "branch" you want to maintain. Because Mercurial will use hard links, this should be fairly quick in most cases.
| Code Block | ||
|---|---|---|
| ||
hg clone /path/to/my/local/integRepo rt-1234
hg clone /path/to/my/local/integRepo rt-5678 |
Basically at this point you manage your own integrations with the graphics repo. Theoretically straightforward, but a lot of busy work!
Another common approach is to use manually managed patches. The way this typical works is that you clone from your repo (such as graphics) and work in that cloned repo. You then do some work. When it is time to switch to another issue that needs to be fixed, you save off the current changes as a patch, revert the changes, and start work on the second issue. When you want to switch back to the first issue, you save off the diff for the second issue, revert all changes, and import the first diff again.
| Code Block | ||
|---|---|---|
| ||
hg clone http://hg.openjdk.java.net/openjfx/8/graphics/rt
cd rt
vi SomeFile.txt
hg diff > rt-1234.patch
hg revert --all --no-backup
vi SomeOtherFile.txt
hg diff > rt-5678.patch
hg revert --all -no-backup
hg import --no-commit rt-1234.patch |
This is by no means foolproof and is a fair amount of work! Wouldn't it be great if there were some tools to automate this work? Well, that is exactly what Mercurial Queues are. Conceptually MQ is one big queue of patches that get applied to your workspace. You can push new changes on, and pop changes off. The above example would be implemented like this in MQ:
| Code Block | ||
|---|---|---|
| ||
hg clone http://hg.openjdk.java.net/openjfx/8/graphics/rt
cd rt
hg qnew rt-1234
vi SomeFile.txt
hg qrefresh
hg qnew rt-5678
vi SomeOtherFile.txt
hg qpop |
SourceTree and TortoiseHg
Instead of using the command line (or perhaps, in addition to) you can also use various visual tools. Atlassian produces one for Mac (and now for Windows) called SourceTree. It has a very simple and intuitive user interface and performs most every task you need when it comes to managing a mercurial repository. You can clone directly within the tool, or open an existing locally cloned Mercurial repository. From within SourceTree you can view the entire history, search through the history, view outstanding changes, commit, push, pull, and perform all the other operations necessary for working with your repo.
Another highly used visual tool for Mercurial on Windows is TortoiseHg. It is very similar visually and in function to SourceTree. For this reason we will focus only on SourceTree in this section, as much of this information also applies to TortoiseHg, or is near enough that you can figure out the rest.
The main window gives a quick view at a glance of the current state of affairs. The branch view shows the history of changes and merges that exist in the repo. You can easily see who has pushed what changsets. If you select a changeset within this view, the details of the changeset are shown below it, listing all the files, and the individual hunks that changed. For the current uncommitted changes, you can revert any hunk (not just an entire file!), and for committed changes you can reverse any hunk (or file), making it easy to back out some changes.
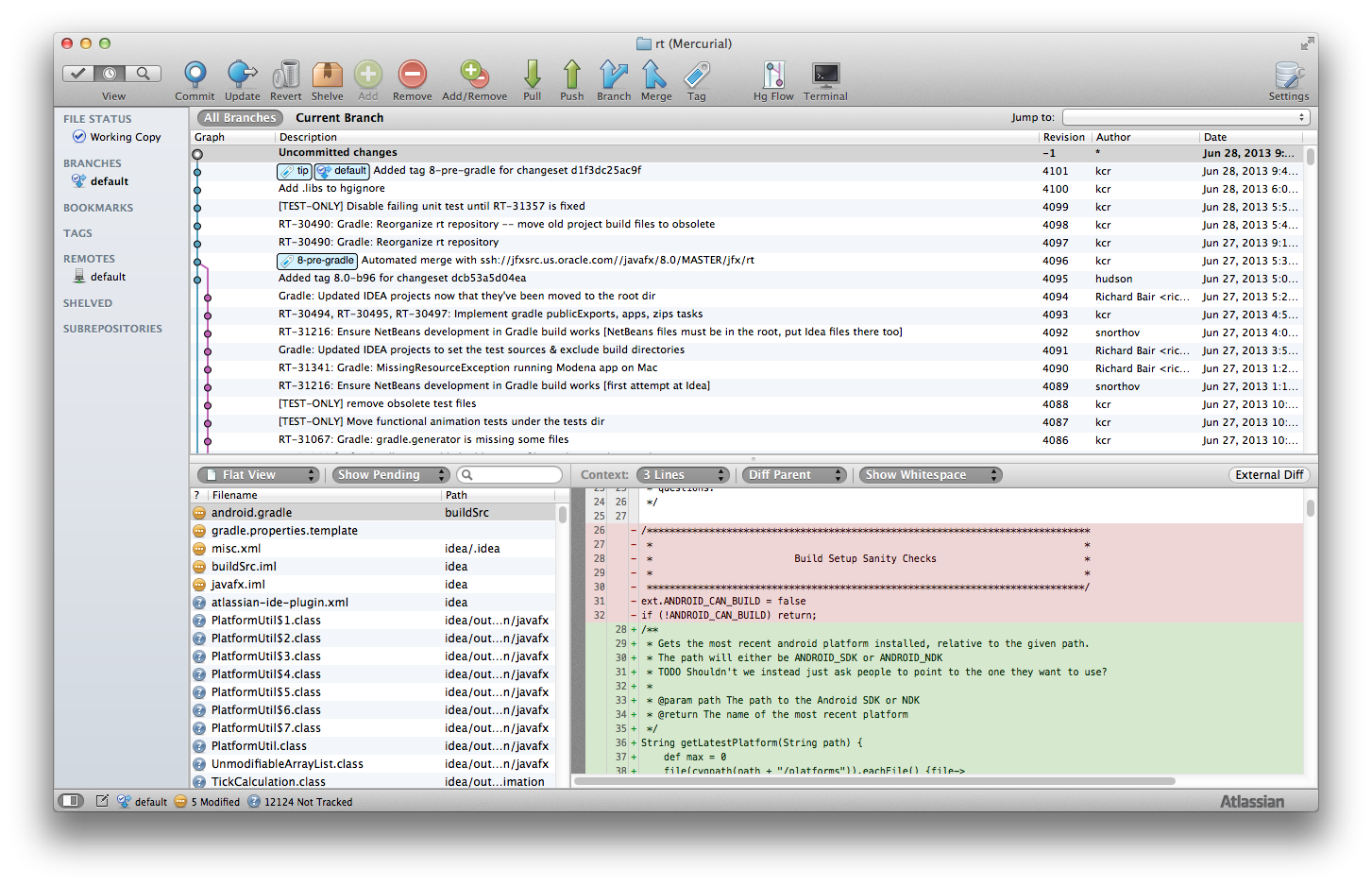
SourceTree also gives you a method for dealing with multiple concurrent changes (the problem we defined in <<Using Mercurial>> above). It is similar to the manual patch style, but using visual tools instead of managing it by hand.
First, we have a very simple project with a single file, Foo.txt. Our repo has a single change set where Foo.txt was created and its single line "First Foo".

We then modify the Foo.txt file. You can see that we've modified the first line to say "Second Foo".
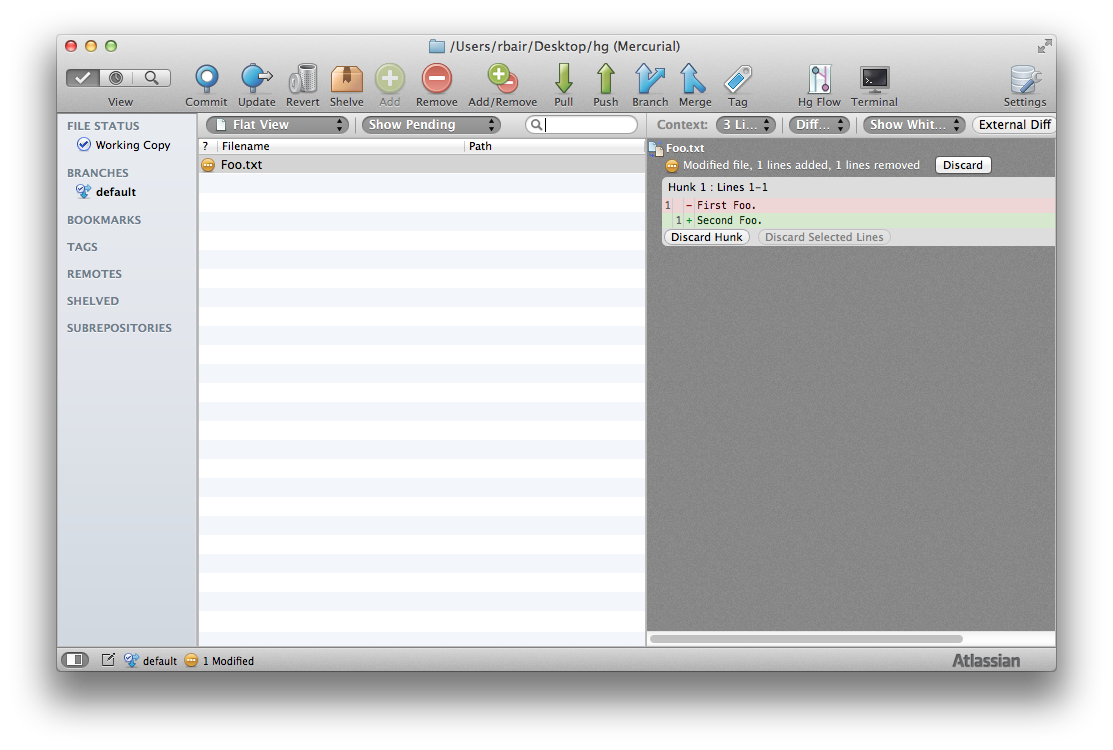
We've now been interrupted and need to switch to another issue. First we select the "Shelve" toolbar button and name our shelved change set
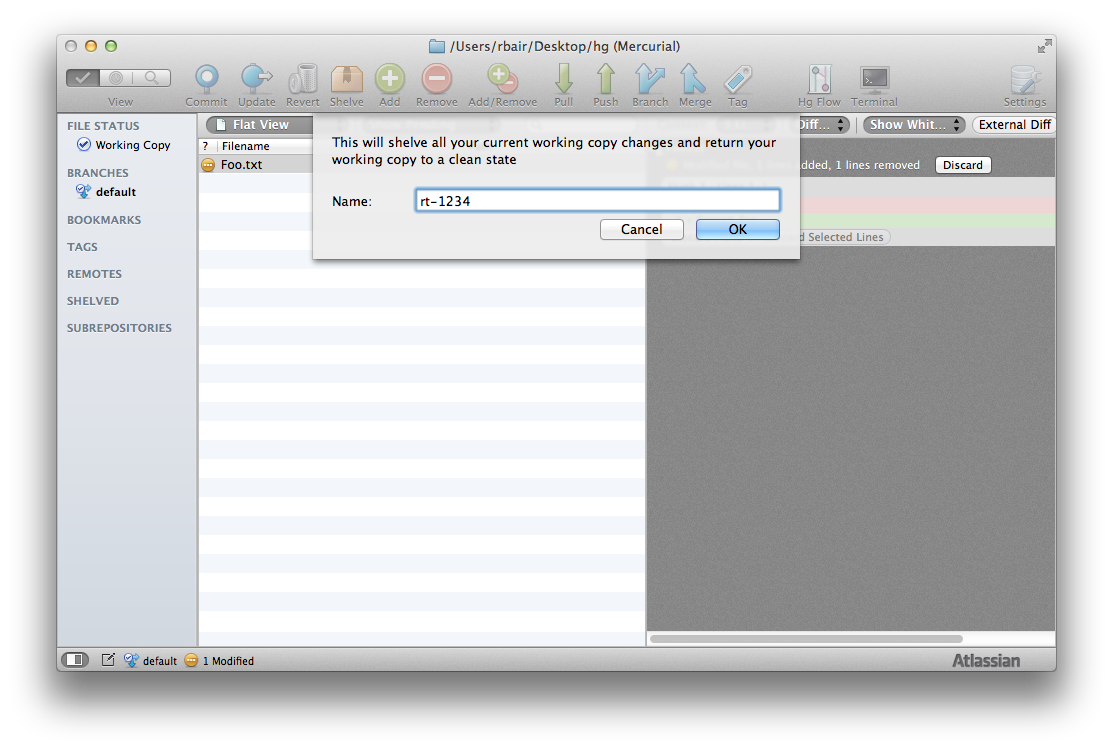
The repo has now been reset to its normal state, and I am free to start working on my second issue, RT-5678. I then am interrupted again and have to switch back to rt-1234 in order to commit the work (perhaps a pending code review has now finished). So, as before, I shelve my changes.

Now I select the shelved rt-1234 and choose to unshelve it.
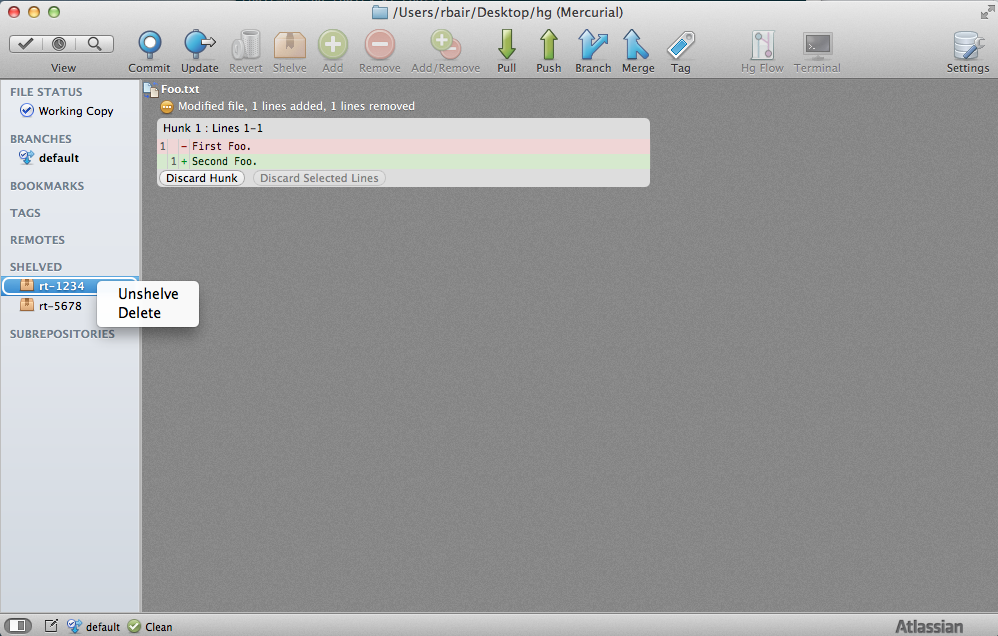
Mercurial with NetBeans
Mercurial with IntelliJ IDEA
Mercurial with Eclipse
...
OpenJFX is a project with committers and contributors from all over the globe. We all live in vastly different timezones and speak very different native languages, and yet all collaborate together on a single code base and a single project. It is sometimes easy for misunderstandings to arise, and sometimes difficult to effectively communicate ideas in a time-sensitive manner. Over many years the software development community has identified a few things that make communicating and collaborating on software easier. We have tried to gather the best practices and bring them all together.
The openjfx-dev mailing list is the main source for free-form communication among all members of the team. The mailing list archives are publicly available. After subscribing to openjfx-dev, you are able to post textual content and easily follow along in all the various issues that are discussed on the list. openjfx-dev is intended as a list for discussing the development of OpenJFX. Every API change request is first created as a JIRA issue, and then a formal request made to openjfx-dev. This is so that everybody can see when a new API is being proposed, and can chime in (primarily on the JIRA issue) with feedback about that API design.
openjfx-dev is also the place to raise architectural issues or questions, or to get help when things aren't building or when some new idea needs to be discussed. It should be a place of respect and moderation in dialog. We're all on the same team, working together to build the best project we can.
Although much dialog occurs on openjfx-dev, the most work and the most data resides in JIRA. Each issue in JIRA contains (or should contain) all of the information pertaining to that issue, such that anybody who reads over the issue can understand the problem, the proposed solutions, the chosen solution (and why it was chosen), the nature and flow of the code review, and when and where the fix went in (or why a fix did not go in) and/or links to that information. JIRA will tell you when an issue is scheduled for work, or if it is unscheduled, or if it is unassigned or to whom it is assigned. Generally individuals are encouraged to vote for issues they feel are important, and to watch any issue that they are interested in and want to participate on.
Most teams also setup JIRA Dashboards for monitoring the progress of a particular release. Some are also using JIRA tags on issues to indicate which "sprint" an issue is assigned to. These dashboards can be searched out by each user of JIRA and added to their home page.

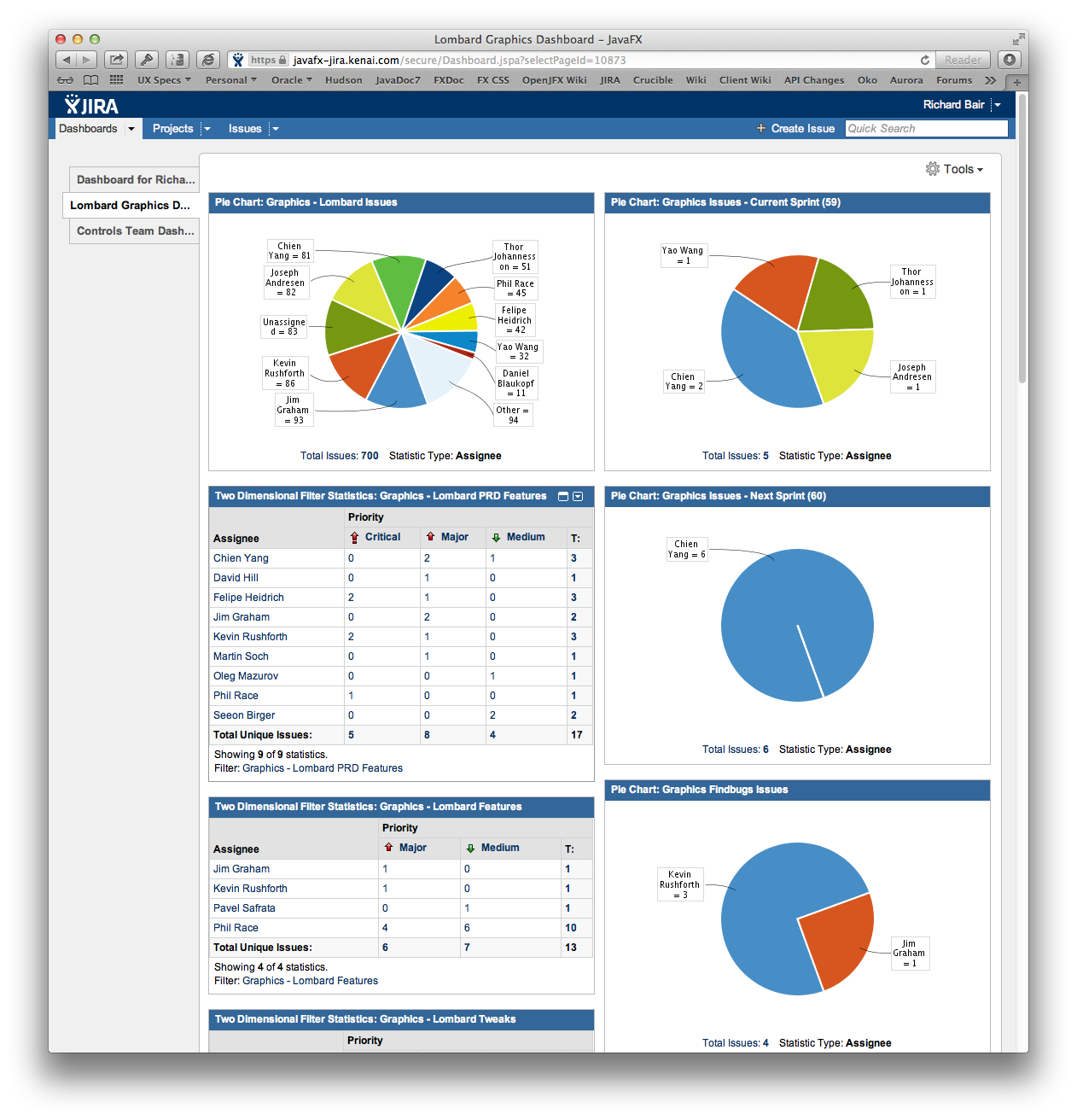
By using JIRA effectively, and by using JIRA dashboards, it is possible for anybody to follow along with development of those issues they are most interested in, and to track the progress of the release and what work is going on now. We attempt to make sure that JIRA is the database of record, meaning that the most accurate up-to-date information is always kept in JIRA.
...
It is important to understand some unique challenges that come with building for the JDK. All Java developers have experience in building applications which rely on a specific JDK, but very few have attempted to build code for the JDK itself. Welcome to an elite band ![]() . As you know, when the JVM starts up, it locates classes on a class path. By default, all JDK classes are first on the class path, before any application code. Normally this is not a problem, because application code is not redefining java.lang.String, for example. However when building JDK code, that is exactly what you are doing. In the case of JavaFX, your version of javafx.scene.Node needs to take precedence over the version of javafx.scene.Node provided by the JDK. Further, since you need a version of the JDK available to build against, you have to deal with the problem of having two versions of most classes on your class path – those provided by the JDK you are building with and those you are providing yourself.
. As you know, when the JVM starts up, it locates classes on a class path. By default, all JDK classes are first on the class path, before any application code. Normally this is not a problem, because application code is not redefining java.lang.String, for example. However when building JDK code, that is exactly what you are doing. In the case of JavaFX, your version of javafx.scene.Node needs to take precedence over the version of javafx.scene.Node provided by the JDK. Further, since you need a version of the JDK available to build against, you have to deal with the problem of having two versions of most classes on your class path – those provided by the JDK you are building with and those you are providing yourself.
Over the years JDK engineers have developed various techniques for dealing with this problem. The issue manifests itself at two times: when you attempt to build, and when you attempt to run code. For now this document will cover the build part of the problem only. The good news is that the OpenJFX Gradle build handles this for you.
The main contributions of JavaFX to the JDK are the jfxrt.jar file and several native libraries. jfxrt.jar is located on the extension class path. This path comes before application code but after code on the boot class path. Because of this, the jfxrt.jar file is located in JDK_HOME/jre/lib/ext/ (ext here stands for 'extension'). Java allows developers to override the location of the ext directory by means of the -Djava.ext.dirs= command line argument. Setting the value of this argument to empty (i.e.: a dangling = sign with nothing after it) effectively clears the ext path. This means that the jfxrt.jar file shipped with the JDK won't be included on the class path by default.
This is how the OpenJFX Gradle build works. Whenever anything needs to be compiled (whether compiling java sources, or running javadoc) we always set the -Djavafx.ext.dirs flag to be empty. This way the code we're building isn't confused by the presence of another nearly identical set of classes on the ext class path (that is, our locally built jfxrt.jar and associated files take precedence over what is supplied by the JDK).
But, there is a wrinkle. Because OpenJFX is not yet completely buildable based on open software, we need to have the jfxrt.jar supplied by the most recent JDK available to us so that any classes or native libraries that we need for compiling and running (so-called 'closed bits' or 'binary stub') is available. But because JDK_HOME/jre/lib/ext/jfxrt.jar has duplicate classes to those we have built locally, we need to make sure that it is placed last on the class path – after all our own code. This way when the JVM is looking for javafx.scene.Node, it will find our version of javafx.scene.Node first, before the one supplied by the JDK. This, again, is handled for you by the Gradle build.
The OpenJFX Gradle build defines a property called BINARY_STUB, which is a path to a jar file containing the closed bits. This file is then added to the end of the class path when building. Ultimately this will not be needed anymore when the rest of the OpenJFX code is open sourced and a fully open build can be done. However for the moment, this is a requirement to get the build to succeed.
When running gradle normally, minimal output is produced. However if you run your gradle command with --info, additional information is printed at the head of the output, including the value of the BINARY_STUB variable. This must be a path to a copy of jfxrt.jar containing the closed bits. Most often this will be the jfxrt.jar file contained in your JDK_HOME/jre/lib/ext/ directory. Again, our build automatically figures this all out based on the value of your JDK_HOME (which by default is the version of Java you used to run the build).
Each week we produce a published "promoted" build of the JDK which includes the week's worth of changes to JavaFX. Generally speaking if you are building from the "master" OpenJFX forest, then you should always use the same corresponding version of the JDK. For example, on Mar 22 2013 we published b82 of the JDK. When building from OpenJFX master for the following week, use b82. This way the open bits and the closed bits are "matched" and your build will succeed.
During the week many changes go into the "graphics" or "controls" forests. It is possible that some corresponding changes are made to the closed bits during the week. This means when you try to build the "graphics" or "controls" forest, you will not have the corresponding "matched" closed bits available to you, and your build may fail. This situation is temporary and will last only until we have finished open sourcing all of the code.
So 9 paragraphs later, we get to the conclusion. You shouldn't have to do anything special to build OpenJFX for the "master" forest – just run gradle. However if you have a problem, the first step to debugging is to run the command with --info and look at the values of JDK_HOME and BINARY_STUB. If these are correct, make sure you have the right "matched" version of the JDK. You will most likely resolve any build problems by taking those steps. If you have additional build issues, let us know on the openjfx-dev mailing list.
Overview
Content Tools